You Can Just Fix Claude Code Issues
Claude Code has a limit of 100 images in its context. I hit this limit recently using Claude Code to generate and review a few dozen keyframe images for a video generation project:
Too much media: 0 document pages + 104 images > 100

From this point I made some overly optimistic (silly) attempts at context trimming without luck:

I could’ve reset the conversation to an earlier message and run compaction successfully from there, but Claude compaction is way too aggressive in my experience. I didn’t want to lose all the discussion we’d had, and /context showed plenty of room left, I just needed to trim out some of the images. I briefly debated between starting a new session (ugh), compaction (ugh), and manually editing Claude’s session files on disk (ugh) before I realized - I can have another Claude just edit its own files on disk.
My prompt:
I'm getting this error in a claude session because too many images are in the thread.
I need you to identify the session and figure out a way to edit the session to remove half of the images (the earlier half).
don't do anything yet, just figure out how to do it. I don't know what session it was but here's the error:
'API Error: 400 {"type":"error","error":{"type":"invalid_request_error","message":"Too much media: 0 document pages + 104 images > 100"},"request_id":"req_011CWVgGyf7wrFEfKSRdZ4UJ"}'
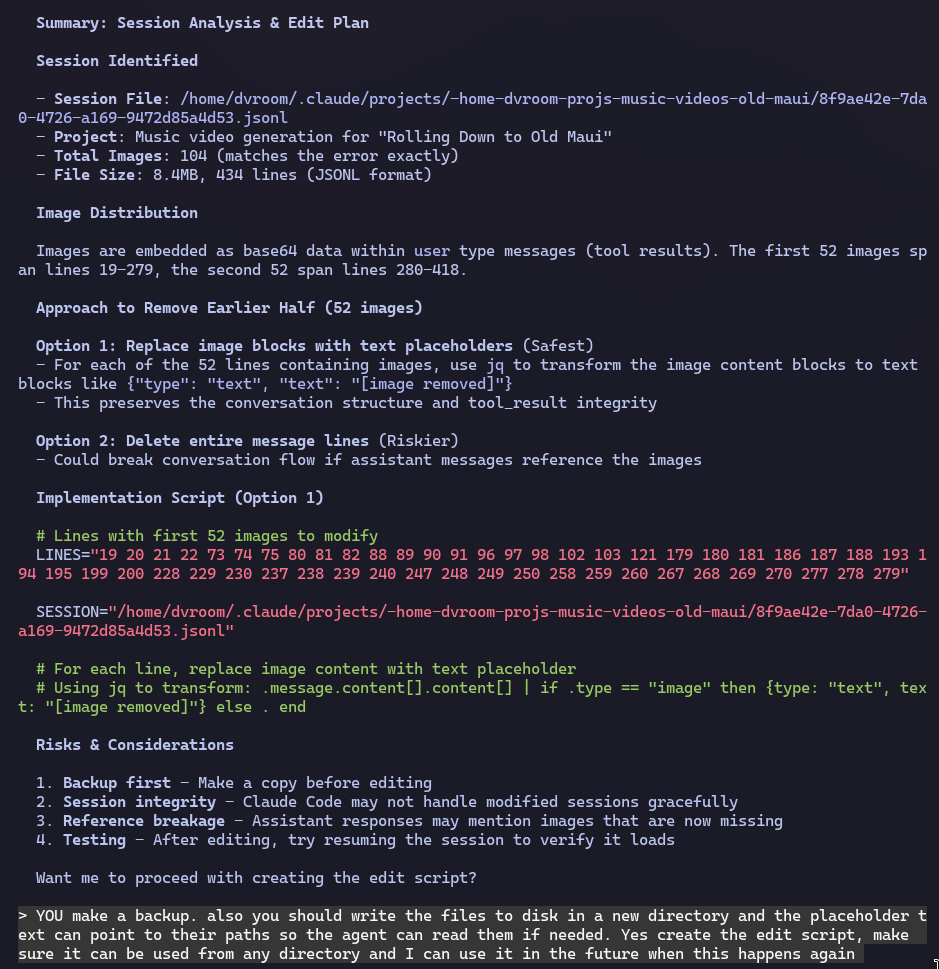
Within a few minutes I was able to resume my session with 52 fewer images in the context. And Claude can choose to read those files if needed, in theory.
There are two threads I want to explore from this experience. The first is best summarized by the creator of Claude Code, Boris Cherny: x.com
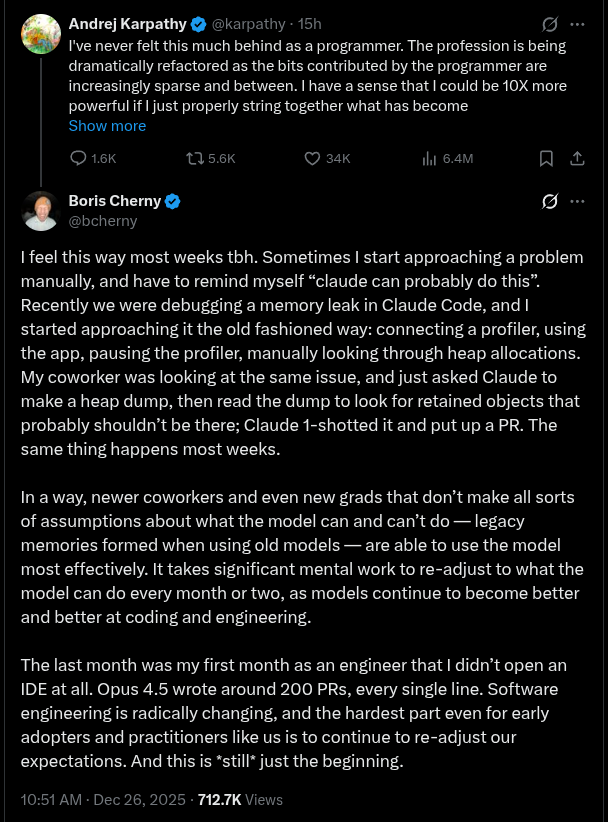
As an Elder Millennial / Late Gen-X engineer I have to keep reminding myself: the instincts I’ve built around the ROI for different types of engineering work are all wrong now. We’ve built up years of defenses against software engineering time-sinks, like spending all our time tweaking our tools and running out of time to build actual products. Some examples:
- Tweaking dev environments
- Managing deployed infrastructure
- Managing Github config
- Writing one-off custom scripts
- Creating media and UIs
I recently installed Omarchy and the whole Arch / Wayland / Hyprland environment is foreign to me, I have to keep reminding myself that the cost-effective way to both learn and modify the environment is to make Claude Code / Codex figure it out in the background while I do something else, not open a dozen Stack Overflow and GitHub Issues tabs and try to piece together my own answers.
The second thread I want to pull on is that context management for these coding agent CLIs has a long way to go. In a year we’re going to look back at the age of anxiety about running compaction as some kind of fever dream. My ideas in this area aren’t particularly original and I’m sure the coding agent CLI teams are working on this currently (Codex has made significant progress on automatic context management recently), but I’ll list some low hanging fruit:
- Move media out of the context as needed - assuming we never actually want the LLM comparing 100 images at once, there’s no value in letting media pile up in the context. Just move it to disk and leave breadcrumbs.
- Move tool responses out of the context as needed - A long session can included hundreds of tool calls and the output volume can be problematic. The agent CLIs typically impose a strict token limit on the responses to help address this, which creates its own issues. Instead of playing a one-dimensional “context explosion” vs “tool response truncation” game we can add a second dimension: recency. Older tool responses have less value than more recent ones, they can be ‘moved’ out of the context to path references on disk. In fact, partial tool responses can be kept in context while referencing the full responses on disk. This leave more room for recent tool responses to be included in the context in full, which avoids issues where the LLM is partially blind to large files and stdout streams.
- Per-message compaction - User messages are almost never going to be a significant factor in context consumption, and user messages should always be considered them most valuable type of context anyway. We should not compact across messages and simply compact large assistant turns.
A universal scoring system could be designed across all three of these, taking into account recency and token use to identify the best candidates for moving to disk and/or compaction. Then just go down the list until the context is within the soft limit.
Ultimately I think a typical ’long’ assistant turn will look something like this after compaction:
You're absolutely right, woozles DO need to be paired with heffalumps whenever possible! This time I will...
# Response truncated - summary:
<summary of assistant turn>
# Highlighted tool calls
[tool call 1]
ls -l src/
[tool call 1 partial result]
main.py
foo/
bar/
[results truncated, see ~/.claude/session-env/<...>/tool-results/<...>]
<...>
There’s also some less-low-hanging fruit in this space - lots of context gets wasted on dead ends and mistakes.
In the small scale, commonly the LLM will make a bad guess at a directory structure or the arguments to a command. Once it figures it out there’s no point keeping the failures hanging around in the context forever, it has working examples now.
On a bigger scale, the coding agent and/or the user may go down dead end paths for some time before correcting direction. It will be important to keep some kind of summary of failures, .e.g <Spent 20 minutes on this approach before realizing it's equivalent to the halting problem, don't do this> but retaining the blow-by-blow nonsense just confuses the LLM.
These could probably be addressed with acceptable accuracy using LLM-as-judge mechanics, though the frequency/granularity for running it would be a challenge to dial-in.